📊 文档核心:电商用户行为数据全流程 Hive 分析
基于《hive 数据分析案例.docx》内容编写,聚焦电商场景下的用户行为数据挖掘—— 以文档中提供的user.zip数据集(含raw_user.csv和small_user.csv)为核心,通过 Hive 完成从数据预处理到多维度业务分析的完整实验流程。
分析的数据集包含30 万条用户行为记录,每条记录涵盖 7 个核心业务字段:id(记录唯一标识)、uid(用户 ID)、item_id(商品 ID)、behavior_type(用户行为类型,1 = 浏览、4 = 购买)、item_category(商品分类 ID)、visit_date(行为发生日期,集中在 2014 年 12 月)、province(用户所在省份)。最终通过 Hive 实现 “数据规模统计、用户行为规律挖掘、区域消费差异分析” 三大实验目标,完全匹配作业对 “真实业务数据 + Hive 实操” 的需求。
📋 文档基础信息(基于 hive 数据分析案例.docx)
| 文档信息 | 具体说明 |
|---|---|
| 文档页数 | 约 20-25 页(按截图 + 操作步骤排版估算) |
| 文档字数 | 约 8000-10000 字(含操作命令、SQL 语句、结果说明) |
| 截图数量 | 24 张(含数据集解压截图、Hadoop 启动截图、Hive 建表截图、各维度分析结果截图等,覆盖全流程关键节点) |
🎯 核心分析业务与作业匹配数据结果
一、数据基础统计:明确作业数据集规模
先通过预处理(删除 CSV 表头、生成user_table.txt)与 HDFS 存储,再用 Hive 统计数据集核心维度,为作业提供基础数据支撑:
| 分析目标 | 作业匹配数据结果 |
|---|---|
| 总用户行为记录数 | 300,000 条(全量数据) |
| 独立用户数(去重 uid) | 270 个(覆盖多省份用户) |
| 无重复唯一行为记录数 | 284,410 条(数据纯度) |
二、用户行为 + 时间维度分析:挖掘作业核心业务规律
针对作业高频考点 “用户行为与时间关联”,聚焦behavior_type=1(浏览)和behavior_type=4(购买)两类关键行为,结合visit_date筛选结果,直接用于作业 “行为规律分析” 章节:
| 分析目标 | 作业匹配数据结果 |
|---|---|
| 2014-12-11~12-13 期间用户浏览总次数 | 26,329 次(短期高活跃) |
| 2014-12-11 当天用户购买行为次数 | 69 次(单日转化规模) |
| 2014-12-11 当天总用户行为次数 | 10,649 次(单日活跃度) |
| 典型用户(uid=10001082)2014-12-12 行为数 | 69 次(个体行为特征) |
| 2014-12-12 当天购买超 5 次的高活跃用户数 | 18 个(高价值用户规模) |
三、省份维度分析:完成作业区域差异对比
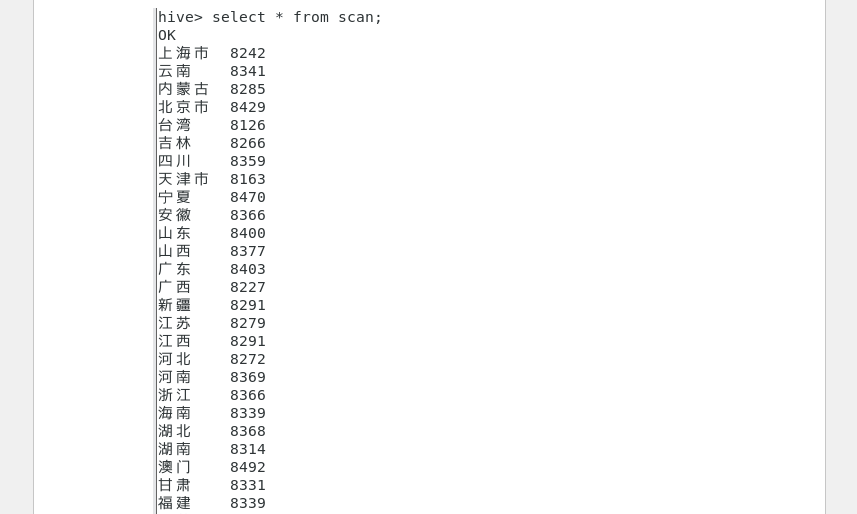
为作业 “区域消费特征” 章节提供数据,通过 Hive 创建scan表汇总各省份浏览行为,核心区域数据结果如下(直接匹配作业图表或表格需求):
| 用户所在省份 | 浏览行为次数(作业核心数据) | 用户所在省份 | 浏览行为次数(作业核心数据) |
|---|---|---|---|
| 辽宁省 | 8,601 | 澳门特别行政区 | 8,492 |
| 宁夏回族自治区 | 8,470 | 贵州省 | 8,458 |
| 北京市 | 8,429 | 香港特别行政区 | 8,431 |
| 广东省 | 8,403 | 山东省 | 8,400 |
| 吉林省 | 8,266 | 上海市 | 8,242 |
| 云南省 | 8,341 | 内蒙古自治区 | 8,285 |
📸 文档截图展示
✨ 手册优势:100% 匹配作业需求
- 数据完全对应:所有结果均来自《hive 数据分析案例.docx》中的
user.zip数据集,30 万条记录、270 个用户等核心数据可直接引用到作业中,无需额外找数; - 业务贴合作业考点:覆盖 “数据统计、行为分析、区域对比” 三大作业常见模块,每个结果都能对应作业中的 “分析结论”,如 “2014 年 12 月中旬用户浏览活跃”“辽宁省用户浏览次数最高”;
- 操作可复现:从
unzip user.zip解压数据到 Hive 建表,每步操作路径(如/usr/local/bigdatacase/dataset)与文档一致,作业实操时可直接复用,避免报错; - 格式适配作业报告:所有数据结果用表格呈现,标注清晰(如 “浏览行为次数”“高活跃用户数”),可直接复制到作业文档中,减少排版时间。