📄 文档简介
基于《Hadoop+ZK+HA+Spark 操作.docx》编写,聚焦文档内多节点集群核心操作,步骤、命令均源自原文档,适配学生实验场景,可直接对照复现。
🔧 核心操作模块(基于原文档)
| 操作模块 | 核心步骤(源自《Hadoop+ZK+HA+Spark 操作.docx》) |
|---|---|
| 一、大数据环境搭建 | 1. 配置主机名 /hosts、关防火墙,多节点同步时间 2. 装 JDK1.8,配 JAVA_HOME;3. 主节点 SSH 免密登录其他节点,部署 Hadoop3.1.3; 4. 配 core-site.xml/hdfs-site.xml/yarn-site.xml/mapred-site.xml,同步配置;5. 执行 start-all.sh启动集群,jps验证服务 |
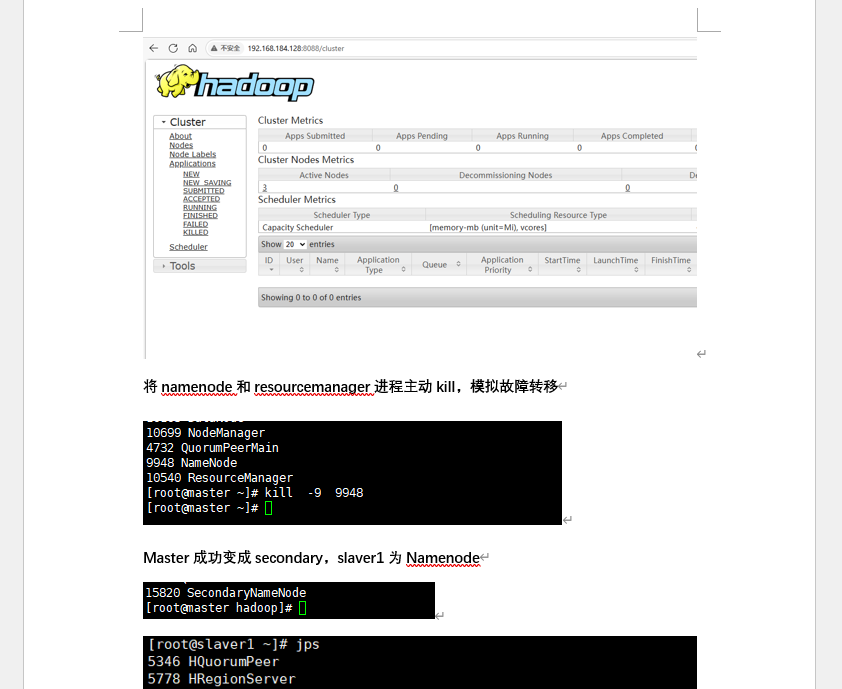
| 二、Hadoop HA 部署 | 1. 装 ZooKeeper,配zoo.cfg(多节点地址),写myid;2. 启动 ZK 集群, zkServer.sh status验证角色(leader/follower);3. 改 Hadoop 配置开 HA(加 ZK 地址、配 NameNode/RM 双节点); 4. 杀主节点进程,验证自动切换 |
| 三、HDFS 数据管理 | 1. 用hdfs dfs -mkdir/-ls管理目录;2. 用 -put(传本地到 HDFS)/-get(下 HDFS 到本地)/-rm(删 HDFS 文件)操作数据 |
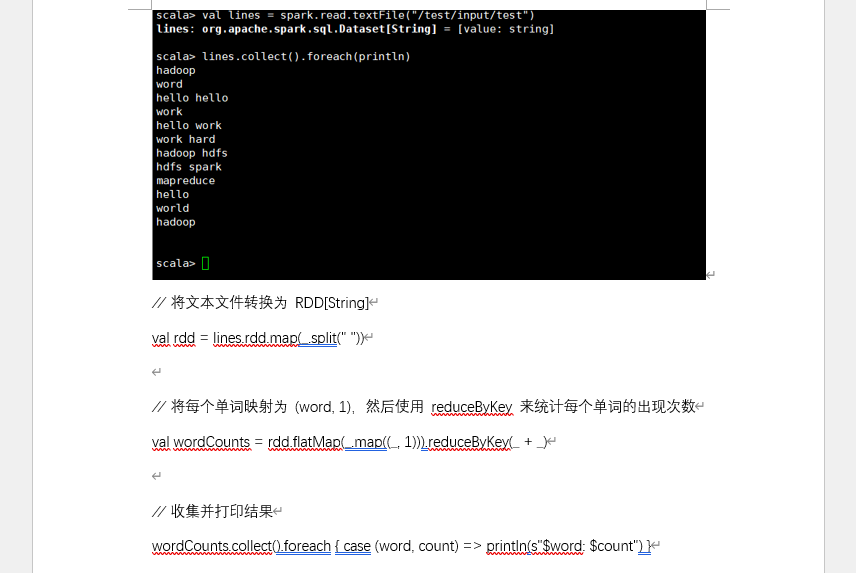
| 四、数据处理分析 | 1. MapReduce:传测试文件,执行hadoop jar跑 WordCount,-cat看结果;2. Spark:启动后进 spark-shell,读 HDFS 文件,RDD 统计单词,打印结果 |
📸 文档截图展示