实验要求:
一、实验目标
- 搭建 3 节点 Hadoop 分布式集群(1 个主节点 + 2 个从节点)
- 掌握多节点环境下 Hadoop 服务的配置与协同方法
- 完成 WordCount 词频统计实验(可使用 Hadoop 自带程序或自编 MapReduce 程序)
- 理解分布式计算的基本流程与核心组件的协作逻辑
二、实验方式
两种方式任选其一,选择方式 2 略有加分优势。
- 方式 1:运行 Hadoop 自带的
hadoop-mapreduce-examples-<ver>.jar程序,实现词频统计 - 方式 2:编写一个简单的 MapReduce 程序,统计文本文件词频
三、提交材料
提交电子版实验报告(PDF 格式),主要包含以下内容:
- 操作步骤与截图(以下条目仅供参考,非强制)
- 集群部署:3 个节点的虚拟机部署,IP 地址与主机名分配,网络连通性测试等
- 基础环境配置:JDK 安装验证、主节点到从节点 SSH 免密登录测试
- Hadoop 集群配置:
- 说明修改过的配置文件
- 关键参数的作用说明
- 集群启动与验证:
- 启动命令
- 验证节点是否正常运行
- WordCount 实验过程:
- 上传文本文件
- 提交任务命令
- 查看统计结果
- 实验心得体会
- 实验中遇到的困难(如网络不通、配置错误)
- 容易出错的地方(如 IP 与主机名未对应、权限问题)
- 对 Hadoop 分布式计算的理解(多个节点如何协作完成存储与计算)
四、注意事项
- 报告重点:展示关键步骤截图,文字说明简明
- 实验核心:能成功搭建 3 节点 Hadoop 集群并运行 WordCount 任务
- 报告格式:
- 无强制格式要求,无模板,尽量美观即可
- PDF,A4 纸张
- 字号建议小四,字体建议宋体及 Times New Roman
- 封面需标注学号和姓名
- 建议在第二页增加目录,以清晰展示实验步骤与报告结构,便于阅读与查找
- 截图尽量用白底黑字(对于终端或命令行界面,可以在软件设置中切换主题或手动调整配色;对于图形化界面,若有深色模式,请切换到浅色模式再截图)
文档页数:共 32 页(含操作步骤 2-31 页、实验心得体会 32 页)
截图数量:30 张(含虚拟机配置、命令行操作、Web 界面、代码编辑等关键步骤截图)
核心主机规划:1 主 2 从架构,主机名、IP 及服务分布明确,如下表:
| IP 地址 | 主机名 | 服务分布 |
|---|---|---|
| 192.168.184.128 | master | NameNode、ResourceManager、DataNode、NodeManager |
| 192.168.184.129 | slave1 | SecondaryNameNode、DataNode、NodeManager |
| 192.168.184.139 | slave2 | DataNode、NodeManager |
一、文档核心内容概览
本文档是一套完整的 Hadoop 分布式集群搭建与 WordCount 实验作业,涵盖环境部署→集群配置→功能测试→代码开发→结果验证全流程,步骤详细且附带实操截图,适配 Hadoop 3.1.3 与 JDK 1.8 版本,可直接作为课程作业参考或实验报告模板。
二、详细目录
一、操作与步骤(2-31 页)
- 安装虚拟机,部署 3 个 CentOS Linux 系统(含 IP 查询操作截图)
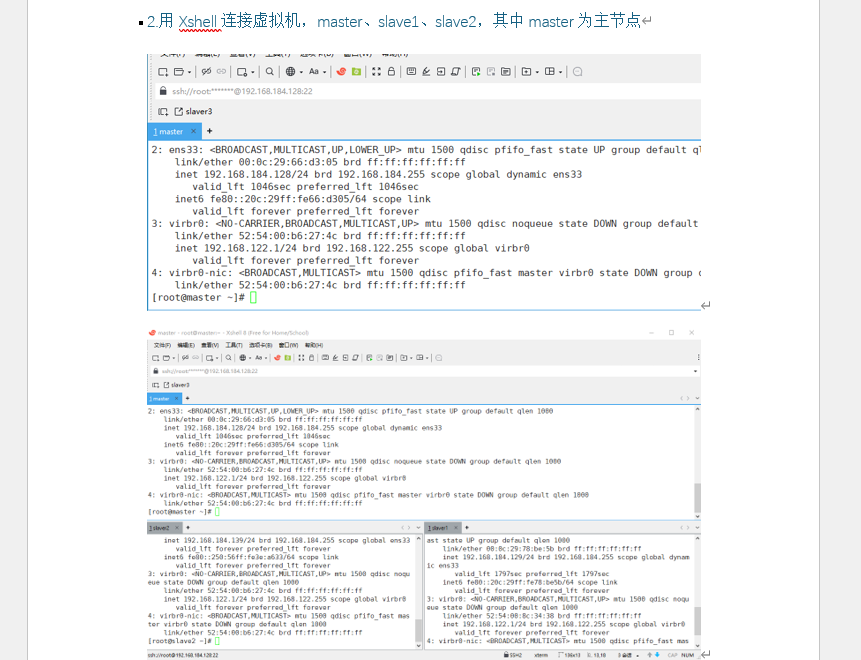
- 用 Xshell 连接 master、slave1、slave2 节点(附 SSH 连接成功截图)
- 配置静态 IP 并编辑 /etc/hosts 文件(含 hosts 文件内容验证截图)
- 关闭三台机器防火墙与 SELinux,测试网络连通性(附防火墙关闭命令截图)
- 安装 NTP 服务并同步时间(使用阿里云 NTP 服务器,附时间同步成功截图)
- 生成 SSH 密钥,配置三台机器免密登录(附密钥生成、免密测试截图)
- 从 master 同步 /etc/hosts 到 slave1、slave2(附文件同步命令截图)
- 下载 JDK 1.8 到 /opt/software 目录(附 JDK 安装包查看截图)
- 解压 JDK 到 /opt/module 目录(附解压后文件列表截图)
- 将 JDK 拷贝到 slave1、slave2 对应目录(附 SCP 拷贝命令截图)
- 下载 Hadoop 3.1.3 并解压,创建软连接(附 Hadoop 目录结构截图)
- 编辑 Java 与 Hadoop 环境变量(附 my_env.sh 配置文件内容截图)
- 生效环境变量并测试版本(附 hdfs version、java version 命令结果截图)
- 编辑 Hadoop 核心配置文件 core-site.xml(附完整配置代码与注释截图)
- 编辑 HDFS 配置文件 hdfs-site.xml(附副本数、SecondaryNameNode 配置截图)
- 编辑 YARN 配置文件 yarn-site.xml 与 MapReduce 配置文件 mapred-site.xml(附配置代码截图)
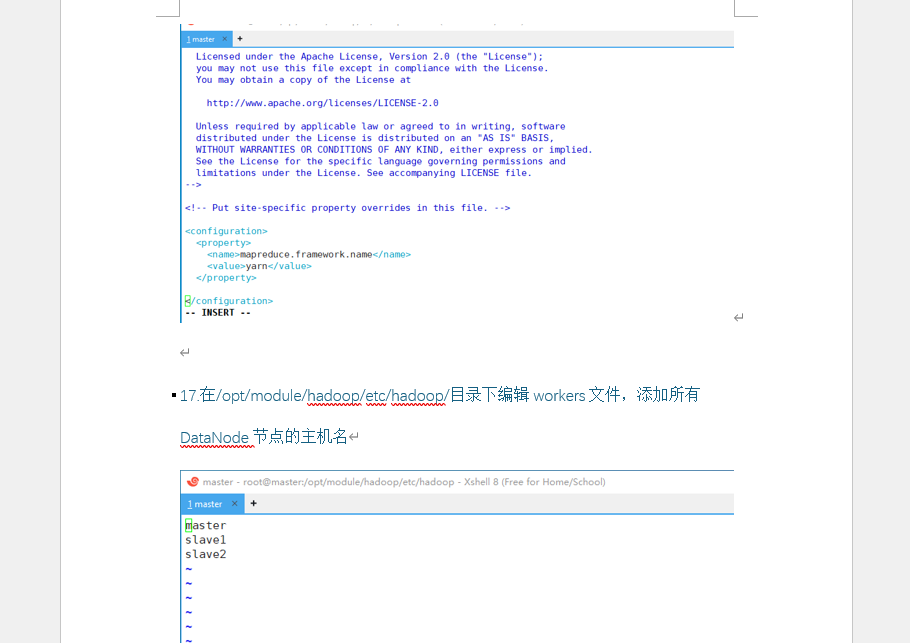
- 编辑 workers 文件,添加 DataNode 节点主机名(附 workers 文件内容截图)
- 同步 Hadoop 配置文件到 slave1、slave2(附批量 SCP 命令截图)
- 在 slave1、slave2 验证配置文件(附 slave 节点配置查看截图)
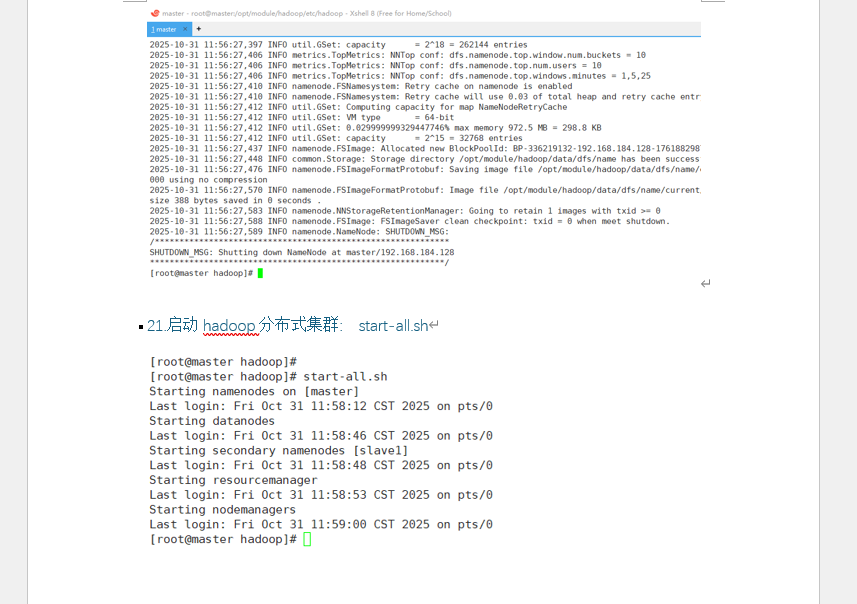
- 在 master 格式化 Hadoop 集群(附 hdfs namenode -format 执行日志截图)
- 启动 Hadoop 分布式集群(附 start-all.sh 启动过程截图)
- 用 jps 命令查看三台机器服务状态(附 master、slave1、slave2 进程列表截图)
- 测试 HDFS 读写功能:创建 /test 目录(附 hdfs dfs -mkdir 命令截图)
- 上传 core-site.xml 到 HDFS 的 /test 目录(附文件上传与查看截图)
- 用 IDEA 开发文本访问时间排序代码(附 pom.xml 配置、Java 代码截图,含 MapReduce 逻辑)
- 打包代码并提交 Hadoop 任务(附 Maven 打包日志、任务提交命令截图)
- 查看 WordCount 任务执行结果(附任务成功日志截图)
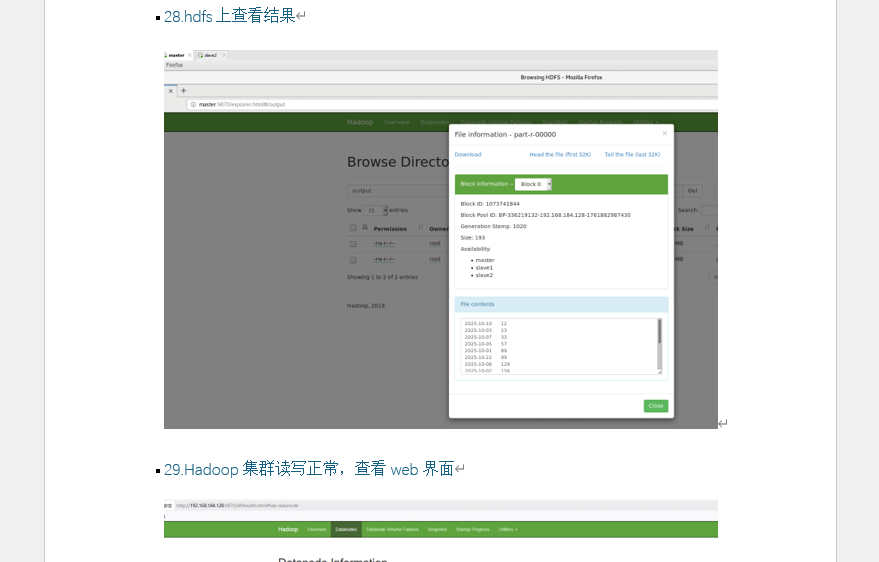
- 在 HDFS Web 界面查看排序结果(附 part-r-00000 文件内容截图)
- 访问 HDFS Web 界面验证集群状态(附 9870 端口 DataNode 信息截图)
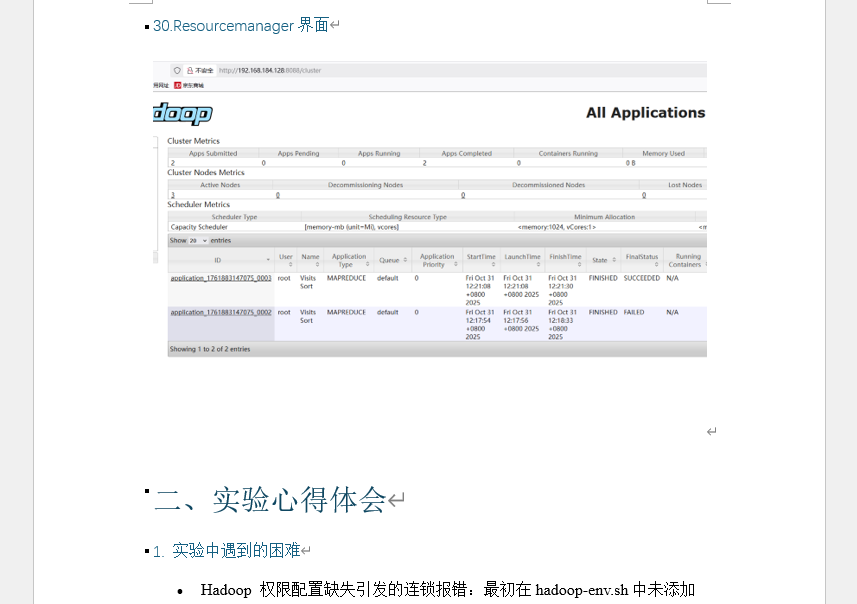
- 访问 ResourceManager Web 界面查看任务(附 8088 端口任务列表截图)
二、实验心得体会(32 页)
- 实验中遇到的困难(权限配置报错、数据格式错误、输出目录重复问题分析)
- 容易出错的地方(隐性配置依赖、数据准备细节、任务生命周期管理疏忽)
- 对 Hadoop 分布式计算的理解(HDFS 存储架构、MapReduce 计算流程、组件协作逻辑)
三、文档核心价值(适配作业需求)
- 步骤完整性:从环境搭建到代码开发,每一步均有明确命令与配置,无操作断层,可直接复现实验
- 截图实用性:30 张截图覆盖关键操作结果(如进程列表、配置文件、Web 界面),作业中可直接引用
- 代码规范性:Hadoop 配置文件含详细注释、Java 代码含类与方法说明,符合作业代码规范要求
- 心得专业性:从问题排查到原理理解,体现实验思考过程,满足作业 “实验总结” 板块要求
适合作为大数据课程作业、实验报告参考,直接下载后可根据实际环境微调 IP、主机名等参数,快速完成作业提交。
四、文档截图