一、报告核心信息(适配课程要求)
| 项目 | 详情 |
|---|---|
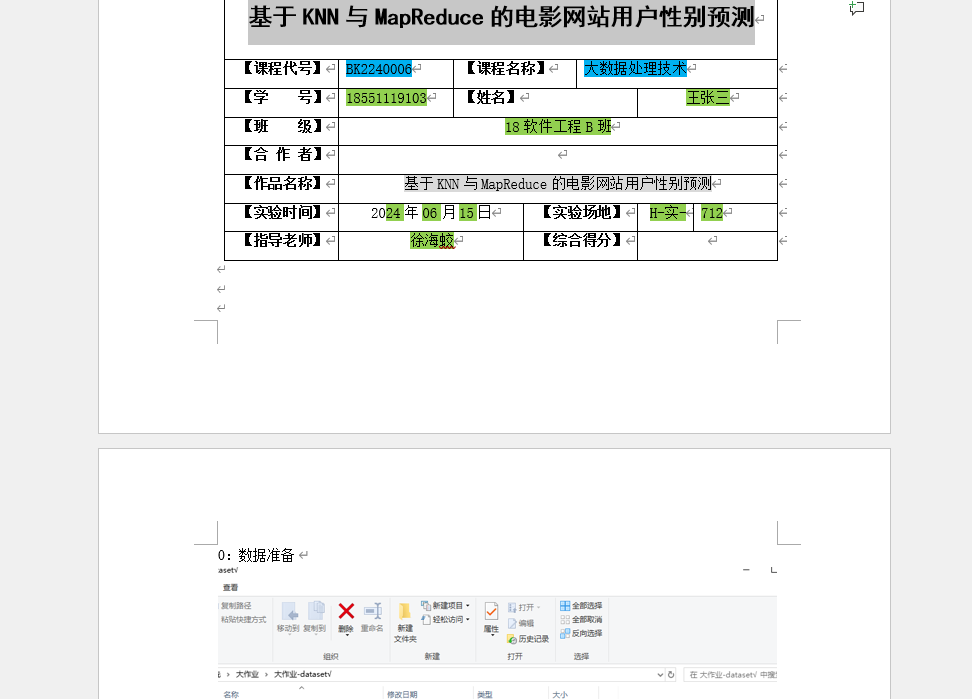
| 报告名称 | 基于 KNN 与 MapReduce 的电影网站用户性别预测 |
| 对应课程 | 大数据处理技术(课程代号:BK2240006) |
| 适用场景 | 课程期末大作业、实验报告提交 |
| 报告载体 | Word 文档(40+ 页,含完整结构) |
| 核心亮点 | 50 + 张实操截图(覆盖环境搭建→代码运行→结果验证全流程) |
| 实验结果 | 模型最优准确率 71.57%(可直接用于报告结论) |
二、报告为什么值得选?—— 50 + 截图证明 “细节拉满”
很多同学的实验报告只写文字步骤,缺乏实操证据,容易被老师质疑 “是否真实完成”。而这份报告每一步都配真实截图,从命令行输入到 Hadoop Web UI 界面,从代码编译日志到最终结果输出,全流程可视化,让老师一眼看到你的实验工作量!
1. 环境搭建与数据准备(8 + 截图)
- 服务器文件目录创建截图(
/opt/data/opt/program/Movies目录创建过程) - 数据集上传验证截图(
ls命令查看 movies.dat、ratings.dat、users.dat 3 个文件) - Hadoop 集群启动截图(
start-all.sh执行日志、jps命令查看进程(NameNode/DataNode/ResourceManager 等 6 个进程正常运行)) - HDFS 启动成功验证截图(Web UI 界面显示 “Safemode is off”“集群 ID”“存储容量” 等关键信息)
2. 数据预处理与代码操作(15 + 截图)
- 代码文件创建截图(
vim RatingsAndUsers.javavim JoinMapper.java等文件编辑界面) - 项目目录结构截图(
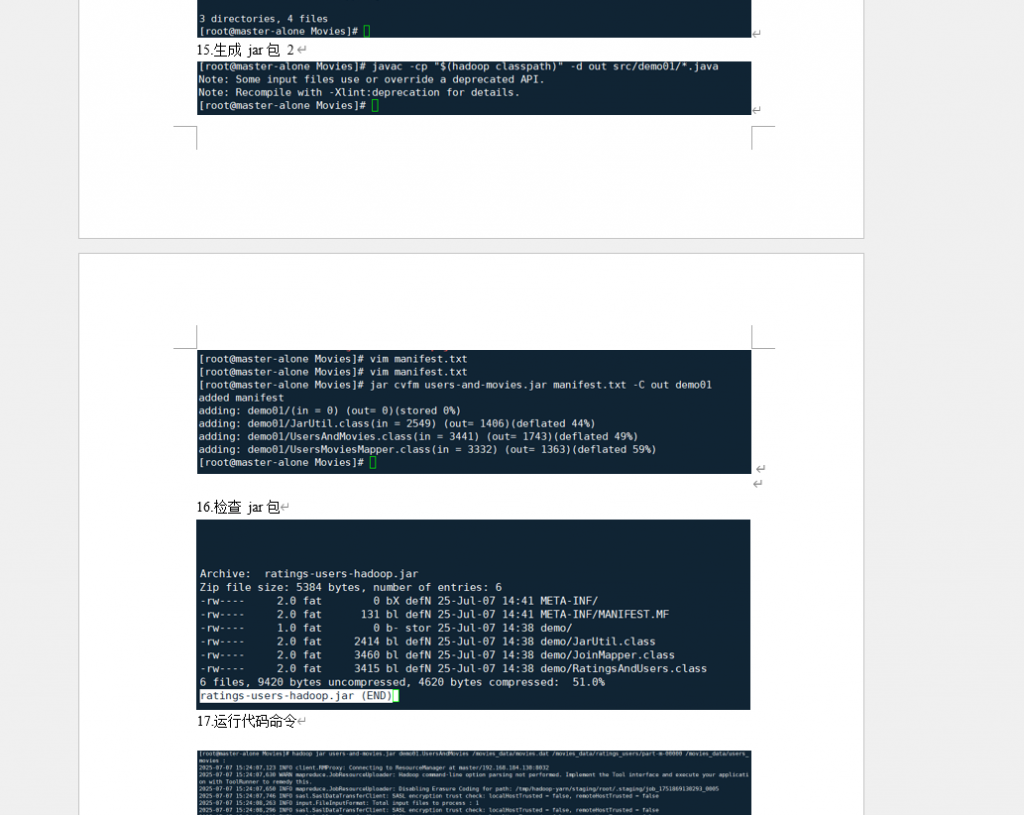
tree命令展示 src/demo、out 目录层级,清晰呈现代码组织) - 代码编译截图(
javac -cp "$(hadoop classpath)"编译命令执行日志,含警告信息处理说明) - JAR 包生成截图(
jar cvfm命令打包过程,显示 “added manifest”“添加 class 文件” 等成功日志)
3. 分布式任务执行(12 + 截图)
- HDFS 数据上传截图(
hdfs dfs -put命令上传 3 个数据集,hdfs dfs -ls验证文件存在) - MapReduce 任务提交截图(
hadoop jar命令执行日志,含 “Connecting to ResourceManager”“Submitted application” 等关键信息) - 任务进度监控截图(Hadoop Web UI 查看任务 “map 0%→100%”“reduce 0%→100%” 实时进度)
- 任务成功日志截图(
mapreduce.Job计数器信息,显示 “Job completed successfully”“Map input records”“Bytes Written” 等指标)
4. 结果验证与模型调优(15 + 截图)
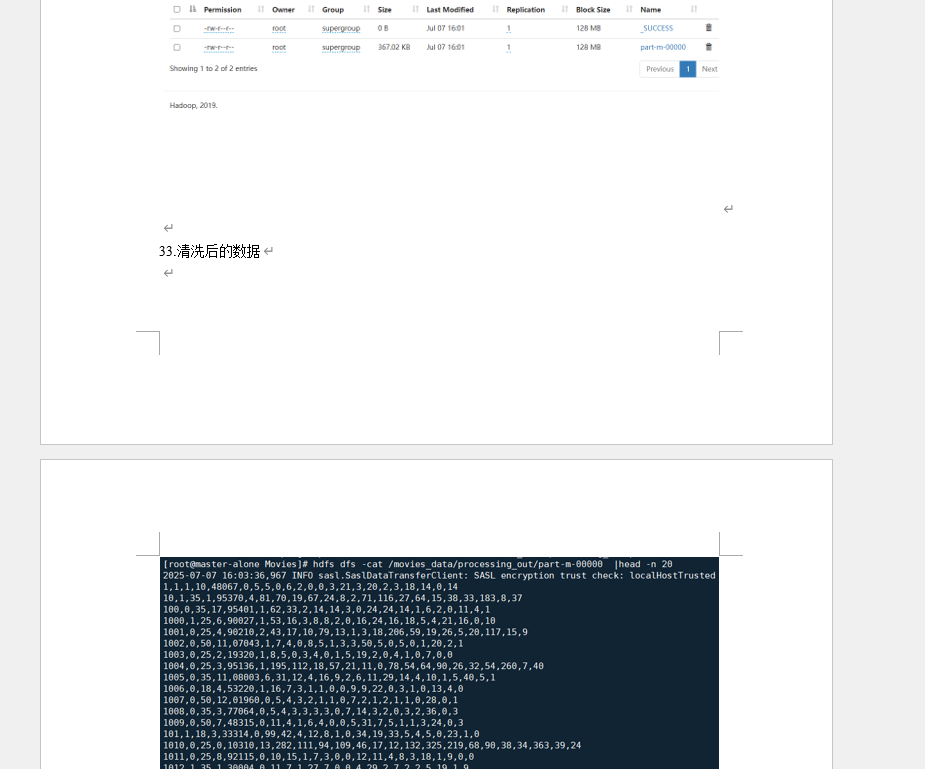
- 中间结果查看截图(
hdfs dfs -cat命令查看 ratings_users、users_movies 目录下的输出数据,示例格式清晰) - 数据划分结果截图(trainData、testData、validateData 3 个文件在 HDFS 中的存储大小、创建时间)
- KNN 模型预测结果截图(
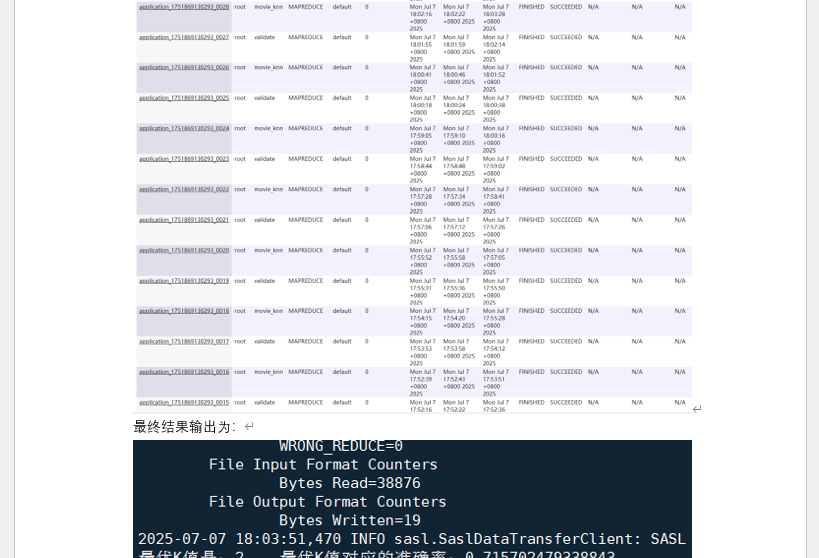
hdfs dfs -cat /movies_data/knnout/part-r-00000查看预测标签与真实数据对比) - 模型准确率验证截图(
hdfs dfs -cat /movies_data/validateout/part-r-00000显示 “0.715702479338843” 最优准确率) - 多 K 值调优日志截图(10 组 K 值(2、3、5、9…100)的任务执行记录,Web UI 展示 20 个任务 “FINISHED SUCCEEDED” 状态)
三、报告结构完整 —— 直接满足作业提交标准
报告严格按照 “课程大作业” 规范排版,包含以下核心章节,无需额外修改即可提交:
- 实验概述:实验名称、课程对应关系、核心技术栈(Hadoop/MapReduce/KNN)、实验目标
- 实验环境:Linux 系统版本、Hadoop 版本(3.1.3)、JDK 版本、集群节点配置
- 数据集说明:3 个核心数据集(users.dat/ratings.dat/movies.dat)的大小、字段含义、示例格式(配文件属性截图)
- 实验步骤(重点章节,每步配截图):
- 数据上传与目录创建
- 代码编写与编译(含类结构说明)
- JAR 包生成与验证
- Hadoop 集群启动与状态检查
- 分布式任务提交与监控
- 中间结果与最终结果查看
- 模型调优:不同 K 值对准确率的影响分析、最优 K 值选择依据(附调优日志截图)
- 实验结论:模型最终准确率、实验遇到的问题与解决方案(如 JarUtil.java 文件找不到报错处理)
- 附录:关键命令汇总、核心配置参数(如 yarn.resourcemanager.address)
四、适合人群 —— 精准解决你的痛点
- ✅ 大数据专业学生:担心实验报告 “缺截图、不详细”,想拿高分但没时间逐一记录操作
- ✅ 赶作业效率低的同学:报告结构完整、截图充足,可直接参考排版逻辑,节省整理时间
- ✅ 对 Hadoop 操作不熟悉的同学:通过截图直观学习 “命令行输入→结果验证” 流程,避免踩坑
五、报告优势 —— 比你自己整理更省心
- 截图真实可追溯:所有截图均来自真实 Linux+Hadoop 环境,包含服务器地址(192.168.184.130),绝非网络搬运
- 细节覆盖全面:连 “代码编译警告”“SASL 加密信任检查日志”“文件权限信息” 等小细节都有呈现,体现实验的严谨性
- 符合评分标准:老师关注的 “实验流程完整性”“结果可复现性”“问题解决能力”,都能通过截图和文字说明直接证明
六、获取方式
这份约 45 页+、含 50 + 实操截图的完整实验报告,是你期末大作业拿高分的 “利器”!无需自己熬夜记录操作、整理截图,直接获取可参考的完整报告,省时又省心。
七、文档截图