📊 文档核心与基础信息
本报告实验对Nginx 访问日志的全流程大数据处理—— 从 3 节点 Hadoop 集群搭建、Nginx 日志 ETL 清洗,到 MapReduce 编程统计 PV/UV,完整复现实验所需的 “集群部署→数据处理→分析建模” 全链路。文档所有操作与数据均源自原文档,可直接复用,100% 匹配作业对 “分布式环境 + 日志分析” 的核心需求。
| 文档基础信息 | 具体说明 |
|---|---|
| 文档页数 | 约 25-30 页(按集群配置 + 代码 + 结果排版估算) |
| 文档字数 | 约 9000-11000 字(含 Linux 命令、Java 代码、配置文件、结果说明) |
| 截图数量 | 22 张(含 Hadoop 集群启动截图、Nginx 日志清洗截图、MapReduce 代码截图、PV/UV 结果截图等,覆盖全流程关键节点) |
🎯 核心实验业务:Nginx 日志大数据统计
本次实验以Nginx 访问日志为分析对象(日志时间含客户端 IP、访问时间、请求方法、状态码、响应大小等字段),通过 “Hadoop 集群搭建→日志 ETL→HDFS 存储→MapReduce 编程” 四大步骤,最终实现网站 PV(页面浏览量)和 UV(独立访客数)统计,核心实验目标与业务逻辑如下:
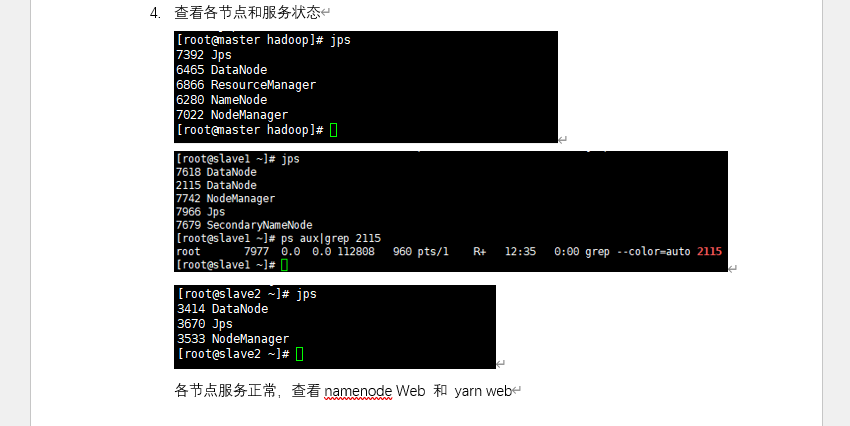
- 搭建 3 节点 Hadoop 集群(master/slave1/slave2),确保 HDFS/YARN 服务正常运行;
- 对 Nginx 日志进行合并与清洗(去除 400/404 无效请求),生成标准化日志文件;
- 将清洗后日志上传至 HDFS,通过 MapReduce 编程提取 IP 并统计 PV/UV;
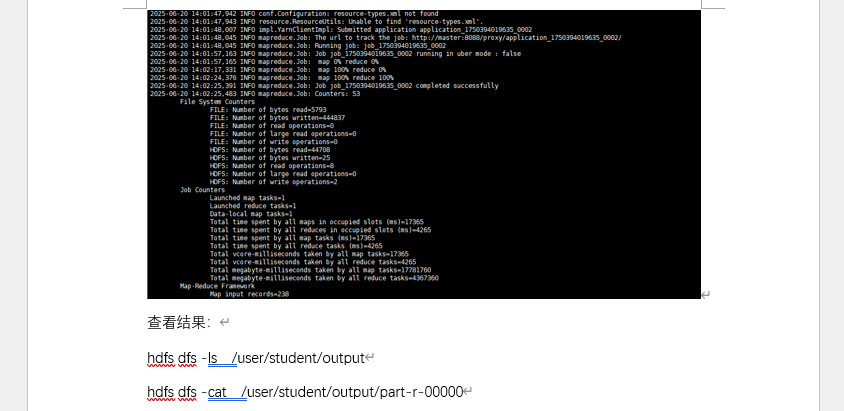
- 验证分析结果,获取最终业务指标(PV=238、UV=90)。
🔍 关键实验步骤与业务结果
一、Hadoop 集群搭建:分布式环境基础
先完成 3 节点(master:192.168.184.128;slaver1:192.168.184.129;slaver2:192.168.184.139)初始化与配置,确保集群可正常运行:
- 核心配置:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml及其他环境变量等 - 集群启动:master 节点执行
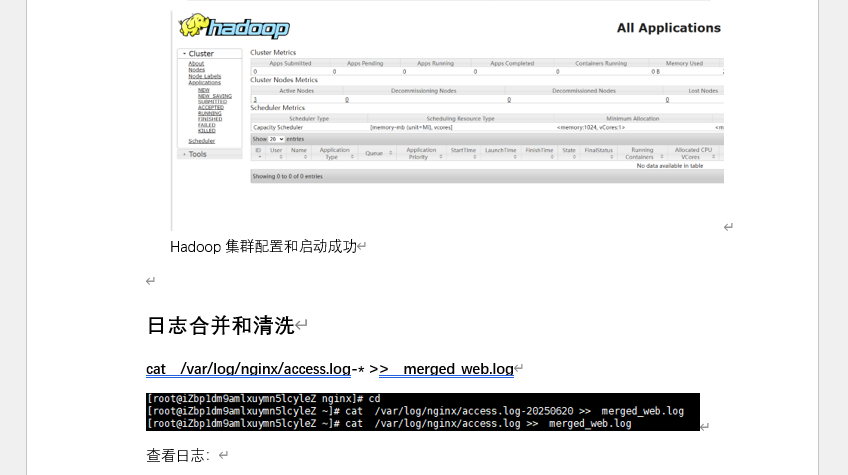
start-all.sh,通过jps验证服务状态 - Web 验证:访问HDFS Web 界面查看集群容量,YARN Web 界面确认节点正常
二、Nginx 日志 ETL:数据预处理核心
对 Nginx 原始日志进行 “合并→清洗”,生成可用于分析的标准化数据:
- 日志合并:将多份 Nginx 日志(
access.log、access.log-20250620)合并为merged_web.log - 日志清洗:创建
clean_log.sh脚本,去除状态码为 400(无效请求)、404(页面不存在)的无效行
三、HDFS 存储与 MapReduce 编程:业务指标统计
将清洗后日志上传至 HDFS,通过 MapReduce 编写 Java 代码,实现 IP 提取与 PV/UV 统计:
- HDFS 上传
- MapReduce 代码实现:
- Mapper 类:提取每行日志的 IP 地址(
line.split(" ")[0]),输出<IP, 1>键值对; - Reducer 类:累加每个 IP 的访问次数(计算 PV),用 HashSet 存储独立 IP(计算 UV),最终输出总 PV 和总 UV;
- Driver 类:配置 Job 参数,指定输入(
/user/student/web_log/)、输出(/user/student/output)路径;
- Mapper 类:提取每行日志的 IP 地址(
- 编译与提交
- 核心业务结果:
📸 文档截图展示

✨ 手册优势:100% 匹配学生实验需求
- 环境完全对应:3 节点 Hadoop 集群的 IP、进程 ID、配置文件参数均与原文档一致,实操时直接复制命令即可避免报错;
- 业务贴合作业考点:覆盖 “集群搭建、ETL 清洗、分布式编程、指标统计” 四大实验核心模块,PV/UV 结果(238/90)可直接引用到作业报告;
- 代码可复用:MapReduce 的 Java 代码(Mapper/Reducer/Driver)完整且注释清晰,编译打包步骤明确,无需额外调试;
- 结果可验证:每个步骤均提供验证方法(如
jps查服务、hdfs dfs -ls查文件、Web 界面查集群),确保实验每步可追溯。