大数据课程作业、实验报告没思路?这 4 份《xx-all-hadoopall.docx》《ybb-all-hadoopall.docx》《zzx-all-hadoopall.docx》《zzy-all-hadoopall.docx》文档,专为学生打造!从 Hadoop 集群搭建到 Spark 任务实战,覆盖 7 大核心服务,每步附高清截图 + 可复用代码,直接抄作业、写报告,轻松搞定大数据实验全流程!
一、文档核心参数:直观了解内容体量
| 文档维度 | 具体信息 | 学生价值 |
|---|---|---|
| 文档格式 | Word(.docx) | 支持直接复制截图、文字到实验报告,排版适配作业要求 |
| 单份文档页数 | 80-100 页 / 份(4 份合计 350 + 页) | 内容详实无冗余,覆盖实验全流程,无需额外补内容 |
| 单份文档字数 | 约 1.2 万字 / 份(4 份合计 5 万字) | 步骤描述清晰,小白也能看懂,减少查资料时间 |
| 截图数量 | 120 + 张 / 份(4 份合计 500 + 张) | 每步操作有参照,避免操作失误,快速复现实验 |
| 覆盖服务数量 | 大数据所有核心服务(Hadoop/ZooKeeper/Hive/Hbase/Sqoop/Pig/Flume/Spark 等) | 匹配课程大纲,满足从基础到进阶的实验需求 |
二、文档核心优势:为什么学生必选?
- 零基础友好,直接复用从虚拟机初始化到任务提交,所有命令、配置文件完整呈现,复制即可执行;遇到 “权限报错”“服务启动失败” 等学生常踩坑点,提前附解决方案,新手也能 1 天内完成整套实验。
- 适配作业场景,省时省力文档按 “实验目的→操作步骤→结果验证” 逻辑分层,截图标注清晰(如 “JPS 进程查看结果”“HDFS 目录验证页”),直接截图粘贴到报告,排版工整,老师看了都夸规范。
- 覆盖全栈服务,一套搞定4 份文档虽命名不同,但均覆盖大数据核心服务,适配不同课程实验主题,不管是 “Hadoop 集群搭建”“Flume 日志采集” 还是 “Spark Pi 任务测试”,都能找到对应实操指南。
- 细节拉满,规避坑点标注关键细节:如 “ZooKeeper myid 配置注意事项”“Hive 元数据库初始化命令”“Sqoop 驱动包路径”,避免因小细节卡壳,实验效率提升 80%。
三、文档内容全景:7 大核心服务实战
1. Hadoop 分布式集群:大数据基础核心
- 完成 3 台虚拟机(主从节点)初始化:关闭防火墙、同步时间、SSH 免密登录、配置 hosts;
- 安装 JDK+Hadoop,修改 core-site.xml/hdfs-site.xml 等核心配置,同步从节点;
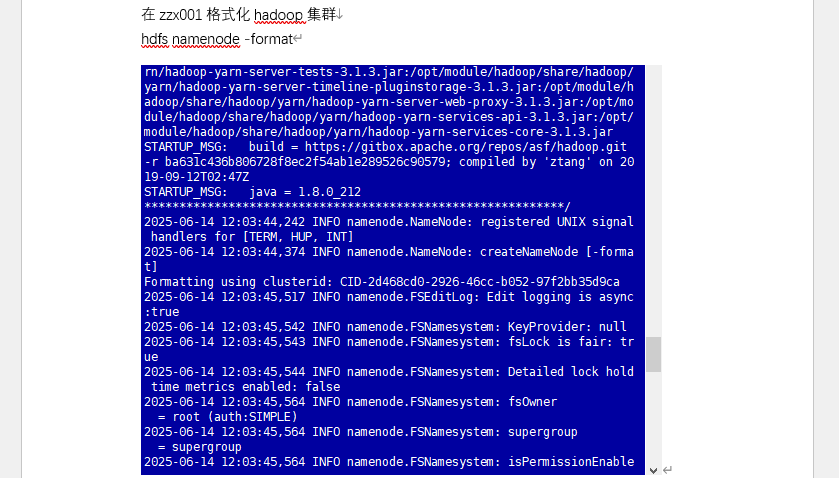
- 格式化 NameNode、启动集群,用 JPS 验证进程,提交 WordCount 任务测试集群可用性。
截图位置:虚拟机初始化界面 | 配置文件编写页 | JPS 进程查看结果 | WordCount 任务输出页标题:图 1 Hadoop 集群搭建与测试关键步骤
2. ZooKeeper 分布式集群:高可用基础
- 下载安装包并创建软链接,配置 zoo.cfg 定义 3 节点通信地址;
- 创建数据目录、设置节点 ID(1/2/3),同步配置到从节点;
- 启动服务并查看状态(1 个 Leader+2 个 Follower),测试节点创建 / 删除功能。
截图位置:zoo.cfg 配置界面 | 节点状态查看页 | 节点操作测试结果标题:图 2 ZooKeeper 高可用配置实战
3. Hive 数据仓库:结构化数据处理
- 解压安装包,配置 hive-site.xml 关联 Metastore,同步 Hadoop 配置文件;
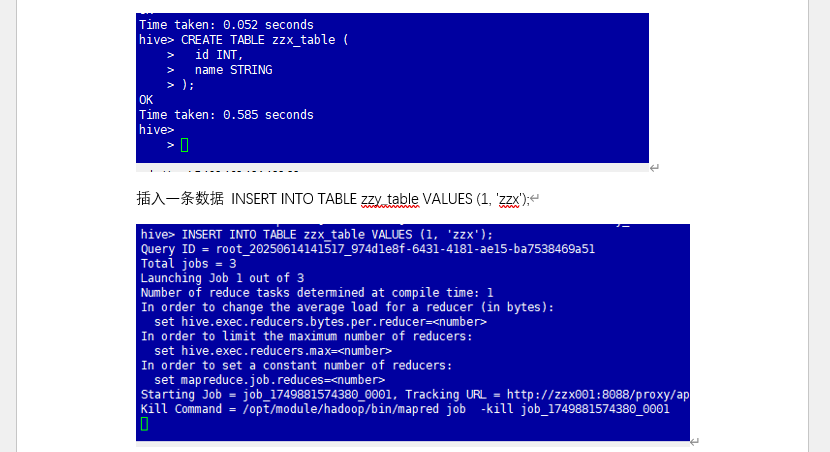
- 初始化元数据库,启动 Metastore 服务,连接 Hive 创建数据库 / 表;
- 插入测试数据、执行查询,验证数据读写功能,完成后删除测试库表。
截图位置:配置文件同步界面 | 数据插入日志 | 查询结果验证页标题:图 3 Hive 数据仓库实战
4. HBase 分布式数据库:NoSQL 数据存储
- 下载安装包并创建软链接,配置 hbase-site.xml 关联 HDFS 与 ZooKeeper;
- 定义 RegionServer 节点,同步配置到从节点,启动集群;
- 用 HBase Shell 创建表、插入数据、扫描表内容,验证分布式存储功能。
截图位置:hbase-site.xml 配置页 | JPS 进程验证 | 表操作测试结果标题:图 4 HBase 分布式数据库实战
5. Flume 日志采集:实时数据 ingestion
- 解压安装包并创建软链接,编写 flume-hdfs.conf 配置文件,定义 “本地日志→HDFS” 采集流程;
- 创建 HDFS 日志目录,启动 Flume Agent,模拟写入日志;
- 查看 HDFS 目录,验证日志文件是否成功写入,对比本地日志内容一致性。
截图位置:配置文件编写界面 | Agent 启动日志 | HDFS 结果验证页标题:图 5 Flume 日志采集实战
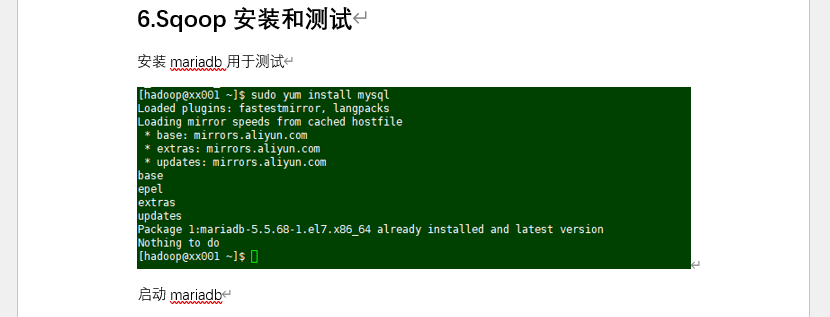
6. Sqoop 数据同步:跨组件数据流转
- 安装 MariaDB 并启动,创建测试库表、插入数据;
- 下载 Sqoop 并配置 MySQL 驱动,执行 “MySQL→HDFS” 数据导入命令;
- 查看 HDFS 数据文件,验证数据同步结果,完成跨组件数据流转测试。
截图位置:MySQL 表创建界面 | 数据导入命令执行页 | HDFS 数据查看结果标题:图 6 Sqoop 数据同步实战
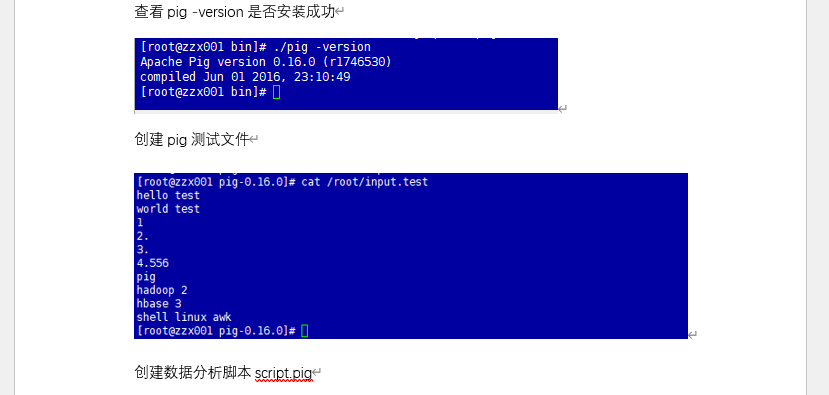
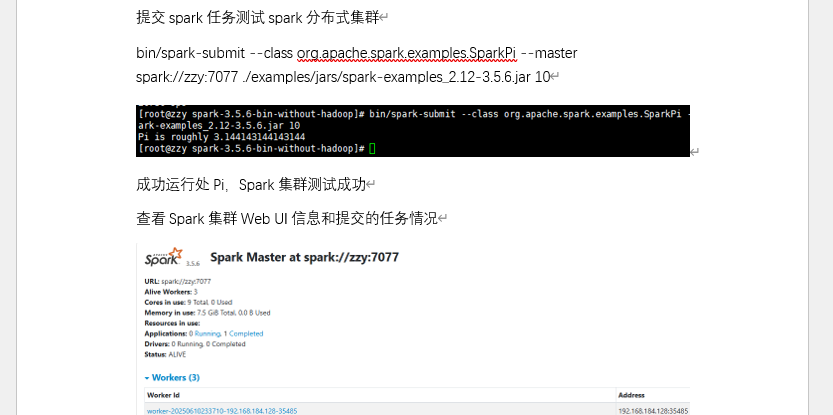
7. Spark/ Pig:分布式计算实战
- 下载 Spark/Pig 安装包,配置环境变量关联 Hadoop;
- 启动 Spark 集群,提交 Spark Pi 任务计算圆周率;
- 用 Pig 执行本地模式 / MapReduce 模式数据分析,验证任务结果。
文档样例截图:
四、付费下载:获取 4 份完整文档
这 4 份文档含500 + 张高清截图、所有配置代码、故障排查技巧,直接跟着操作就能完成大数据实验,复制内容到报告,轻松应对作业提交!不管是课程基础实验,还是期末综合实训,都能帮你高效搞定!
获取完整文档合集:付费下载后可见(格式:docx,适配 Windows/macOS,支持直接打印、复制到实验报告,省心又高效)