(含核心步骤 + 操作截图,3 分钟跑通实验)
🔍 前置说明
本指南基于已配置好的虚拟机镜像,无需手动部署环境,按以下步骤操作即可快速验证 Hadoop 数据清洗与 Flink 实时分析功能。所有步骤均附实操截图,确保零踩坑!
1️⃣ 下载与解压镜像
- 下载镜像压缩包(如
hadoop+flink+code.zip),保存至本地非中文路径(下载地址在文章结尾) - 右键解压,得到
.ova或.vmx格式的虚拟机文件⚠️ 注意:解压路径不要含空格或特殊字符(如 “我的文档”“桌面”),否则可能导致导入失败
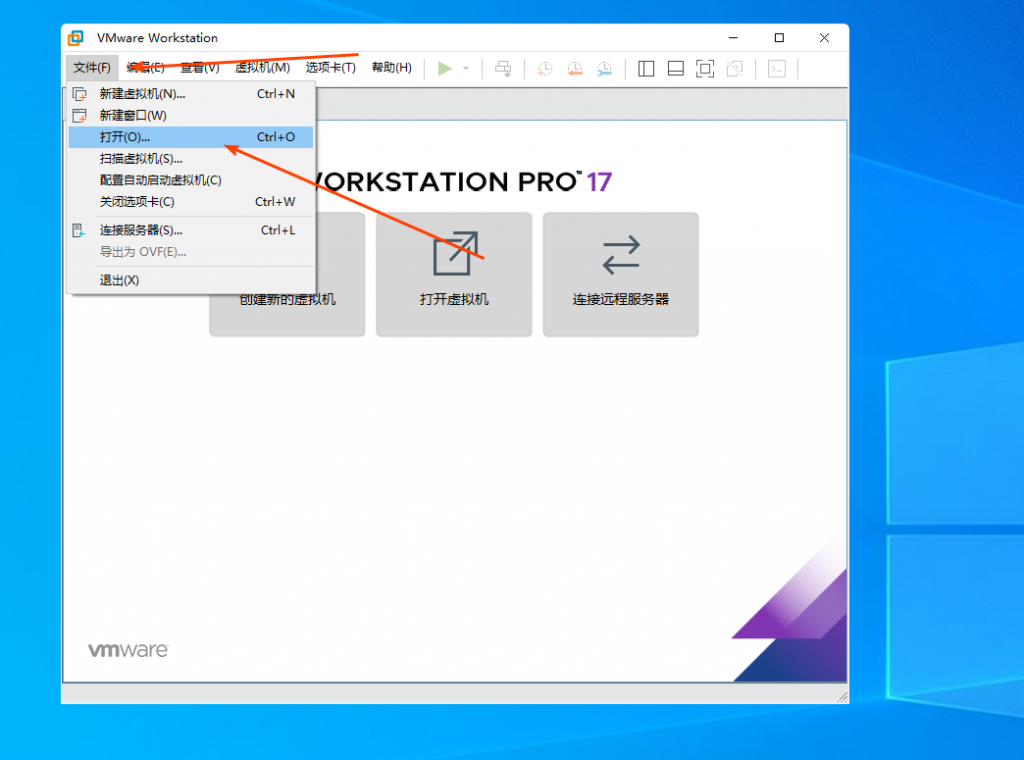
2️⃣ 导入 VMware 并启动
- 打开 VMware Workstation,点击顶部菜单 「文件」→「打开」
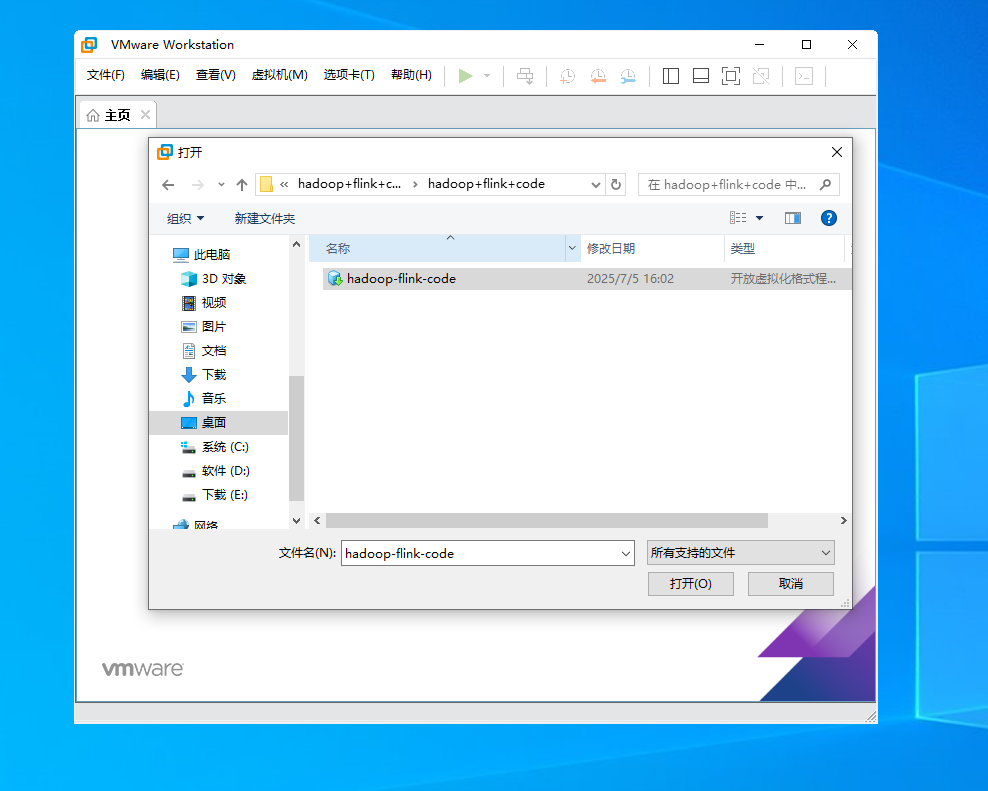
- 选择解压后的镜像文件(如
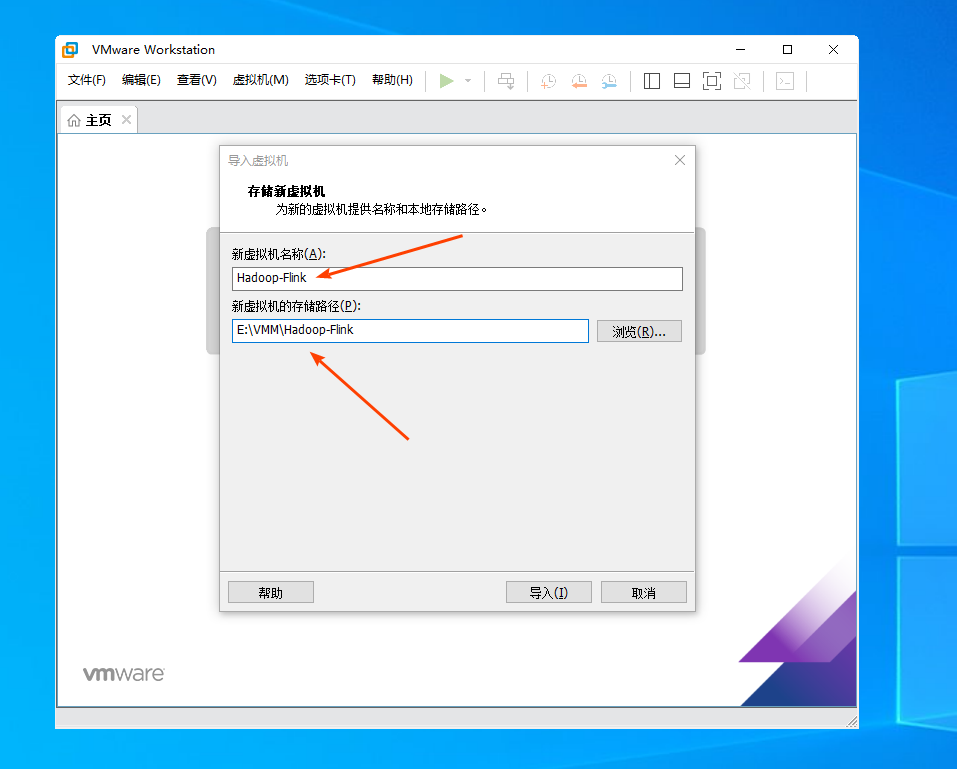
hadoop+flink+code.vmx- 自定义虚拟机名称(如
Hadoop-Flink,便于区分) - 存储路径默认即可(建议剩余空间≥20GB)
- 自定义虚拟机名称(如
- 点击 「导入」,等待进度条完成(约 1-2 分钟,取决于电脑性能)
- 导入成功后,点击 「开启此虚拟机」,等待系统启动(首次启动可能较慢,耐心等待至桌面加载完成)

3️⃣ 登录系统并验证 Hadoop 环境
- 桌面显示登录界面时,使用以下账号密码登录:
- 用户名:
root - 密码:
root123(输入时屏幕无显示,输完回车即可)
- 用户名:
- 右键桌面空白处,选择 「Open Terminal」 打开终端
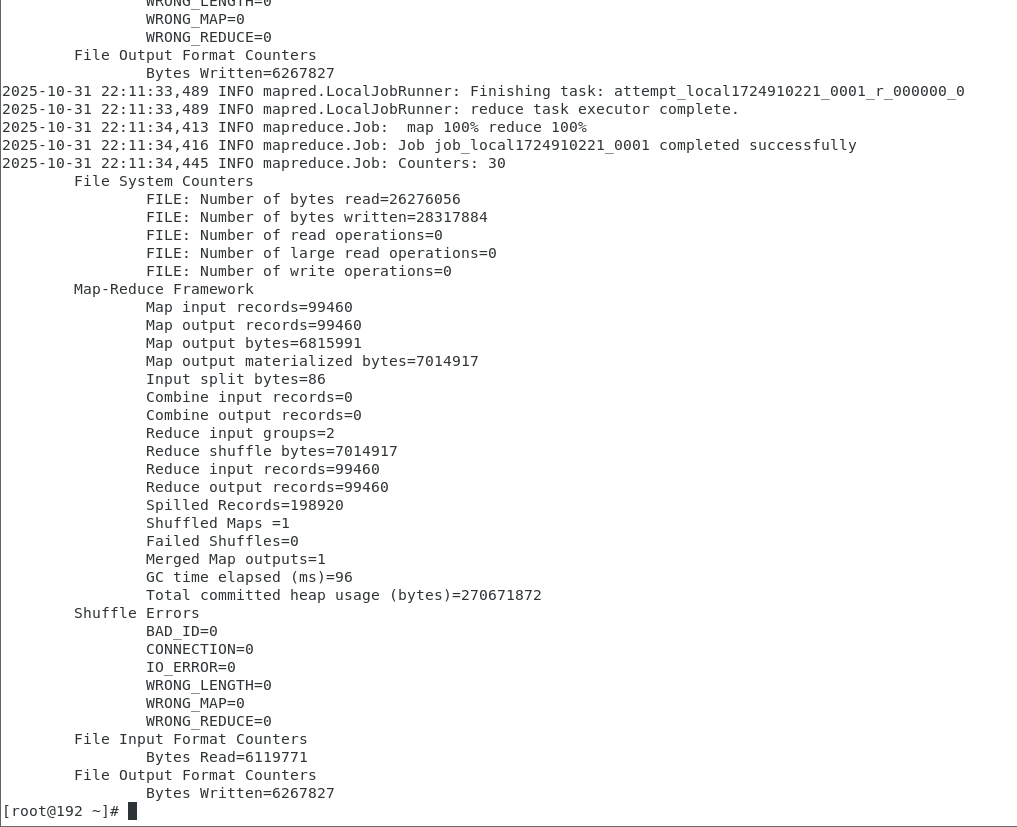
- 执行 以下Hadoop 数据清洗命令(一键运行,无需修改路径):
hadoop jar /opt/program/dataclean/dataclean-job.jar DataCleanJob /root/retail.csv /root/shopoutput- 等待命令执行完成(终端显示
Successfully即成功)
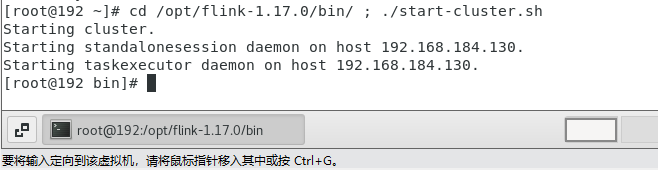
4️⃣ 启动 Flink 集群
在终端输入以下命令,启动 Flink 分布式集群:
cd /opt/flink-1.17.0/bin/ && ./start-cluster.sh
- 启动成功后,终端会显示
Starting cluster.提示 - 可通过
jps命令验证进程(应包含StandaloneSessionClusterEntrypoint和TaskManagerRunner)
5️⃣ 提交 Flink 实时分析任务
在终端执行以下命令,提交电商数据实时分析任务到 Flink 集群:
bash
/opt/flink-1.17.0/bin/flink run -c com.example.RetailDataAnalysis /opt/program/shop-test/target/retail-job.jar
- 提交成功后,终端会显示任务 ID(如
Job has been submitted with JobID ...)
6️⃣ 查看 Flink 任务实时结果
- 在虚拟机桌面左上角,点击 「应用程序」→「Internet」→「Firefox」 打开浏览器
- 在地址栏输入:
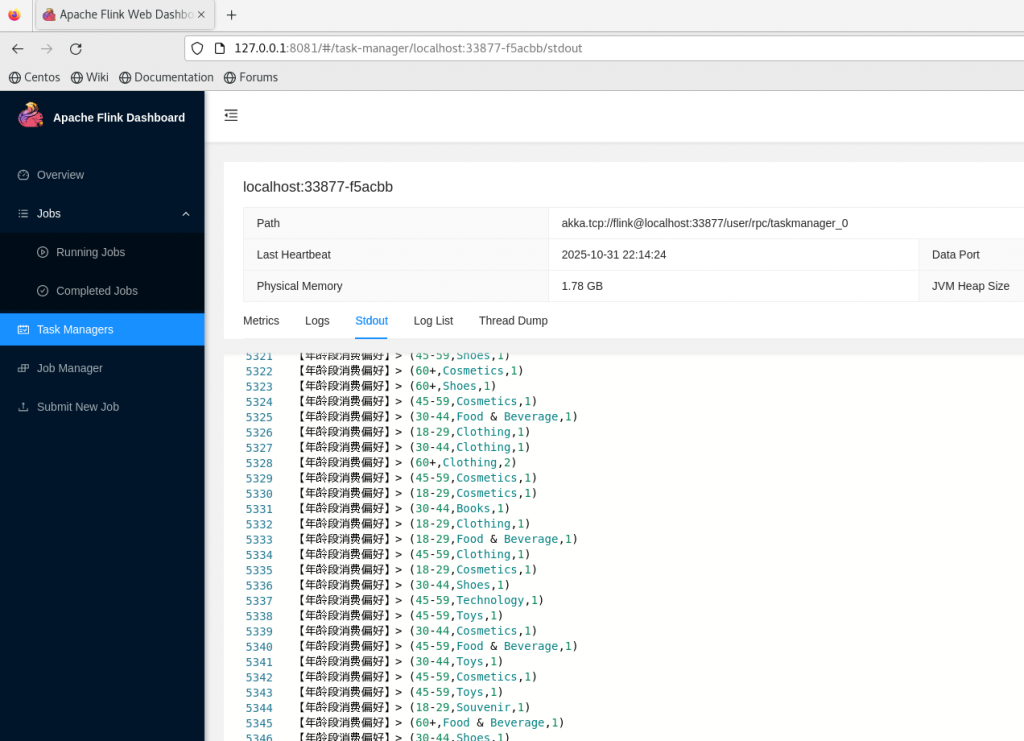
http://127.0.0.1:8081(Flink Web UI 默认地址),回车访问 - 查看实时汇总数据:
- 点击左侧菜单 「Task Managers」
- 右侧列表中点击
localhost:xxx开头的任务节点 - 在新页面中找到 「Stdout」 标签,即可查看实时输出的分析结果(如商品销量 Top10、用户行为统计等)
💡 关键补充说明
- 数据清洗输出路径
/root/shopoutput若已存在,再次运行 Hadoop 命令会报错,需先删除,在终端执行以下命令即可:hdfs dfs -rm -r /root/shopoutput - 所有步骤均基于虚拟机内预设路径,无需修改配置,直接复制命令即可执行
按以上步骤操作,5 分钟内即可从 “导入镜像” 到 “查看实时分析结果”,全程零手动配置,完美适配课程作业演示与验证需求!
0️⃣ 【付费获取】虚拟机镜像下载
📌 核心环境已预装:Hadoop 3.3.4 + Flink 1.17.0 + 电商数据集 + 可直接运行的分析代码,省去 3 天手动配置时间!
[…] 不想手动配置环境?推荐搭配我的另一篇教程 《Hadoop+Flink 电商分析集群 虚拟机镜像极速部署指南》 ,现成镜像导入 VMware/VirtualBox,3 分钟启动集群,直接跑通所有实验步骤! […]