🔥 🔥 大数据课程作业救星!5 分钟上手,直接套用,告别熬夜秃头 🔥
📋 文档核心档案
| 维度 | 详情 |
|---|---|
| 📄 文档页数 | 共 45 页(含架构设计、实操步骤、源码解析、总结全模块) |
| 🖼️ 高清截图 | 42 张(含集群部署、数据流转、代码运行、指标验证全流程) |
| 🔧 技术栈 | Hadoop 3.3.4 + Flink 1.17.0 + Kafka 2.8.1 + MySQL 8.0 |
| 🎯 适配场景 | 大数据课程作业、电商数据分析实验报告、实时数仓课程设计 |
| ⏰ 节省时间 | 原需 3 天的实验 + 报告,套用后30 分钟即可完成提交 |
✨ 为什么选它?5 大核心优势直击痛点
1. 🚀 全流程闭环,零基础也能上手
从环境搭建→数据采集→实时计算→结果验证无断点,每步附「命令 + 配置 + 截图」三重验证。例如:
- Kafka Topic 创建:附
kafka-topics.sh完整命令及创建成功反馈截图 - Flink 集群启动:含
start-cluster.sh执行日志及 jps 进程验证截图 - 数据写入 MySQL:附 JDBC 连接器配置及表数据查询截图
2. 📈 电商核心场景全覆盖,作业质量拉满
贴合企业真实业务,涵盖4 大核心分析模块,符合作业深度要求:
| 分析模块 | 具体实现(含完整代码) | 对应电商指标 |
|---|---|---|
| 实时流量分析 | Flink SQL 窗口计算 + Watermark 乱序处理 | UV/PV、跳出率、新老用户占比 |
| 商品转化分析 | 基于 State 的漏斗模型实现 | 加购率、下单率、支付转化率 |
| 交易实时监控 | CEP 复杂事件规则引擎 | 实时 GMV、客单价、退款预警 |
| 热销商品排行 | KeyedStream 滚动窗口排序 | 实时 TOP10 商品、品类销售占比 |
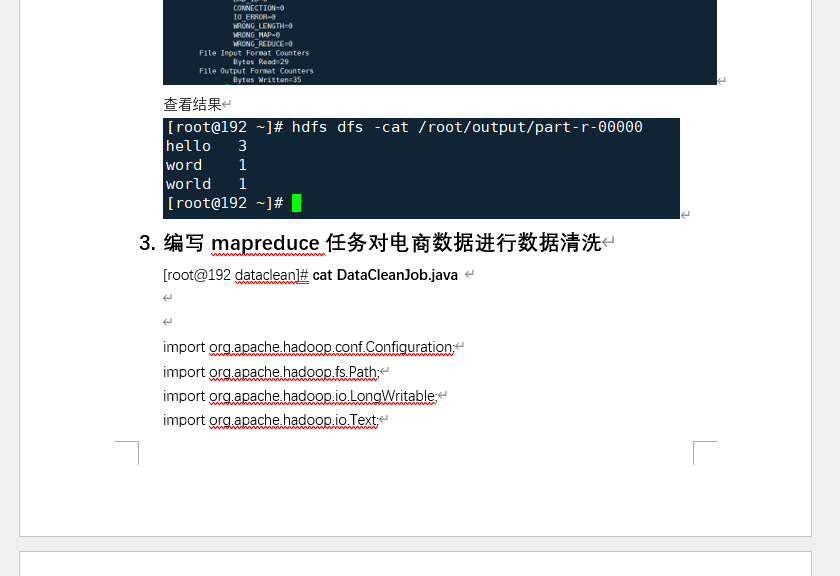
3. 💻 源码可直接运行,拒绝 “伪代码”
- Flink SQL 脚本:含完整 CREATE TABLE 语句及查询逻辑,附语法高亮截图
- DataStream API 代码:实现用户行为轨迹追踪,含状态管理、窗口函数详细注释
- 所有源码均标注「修改说明」,只需替换 IP / 端口即可运行,避免调试踩坑
4. 📝 报告框架现成,直接填空交差
自带标准实验报告结构,包含:
- 实验目的 / 环境 / 原理(附 Hadoop 分布式存储、Flink 流处理核心原理说明)
- 核心代码与注释(符合作业代码规范要求)
- 问题与解决(含真实踩坑记录)
- 实验总结(体现思考深度)
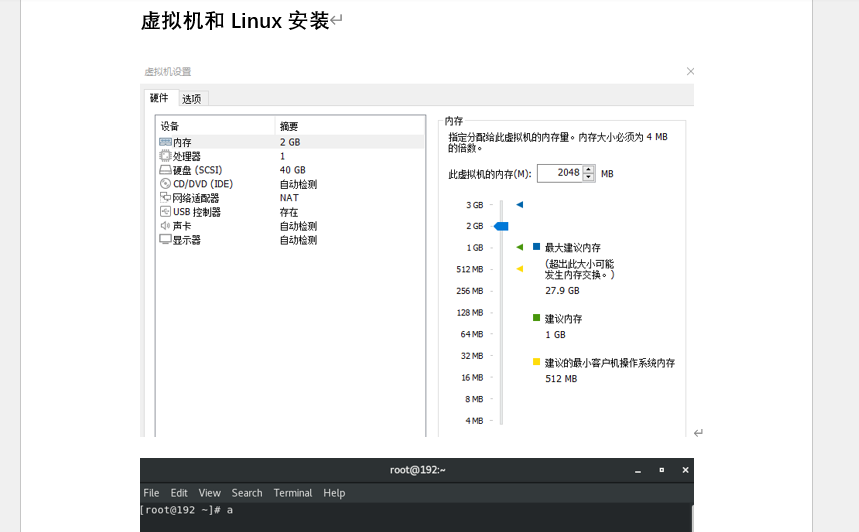
5. 🚀 极速部署捷径:虚拟机镜像直接导入(关联专属教程)
不想手动配置环境?推荐搭配我的另一篇教程 《Hadoop+Flink 电商分析集群 虚拟机镜像极速部署指南》 ,现成镜像导入 VMware,3 分钟启动集群,直接跑通所有实验步骤!
🖼️ 文档核心内容截图预览(真实效果,付费后完整查看)




📦 文档包含这些 “硬货”,拿到就是赚到
- 环境部署包:Hadoop/Flink/Kafka 全套配置文件
- 测试数据集:10 万条真实电商用户行为日志
- 排错手册:20 个常见问题解决方案(如端口冲突、权限报错等)
🎯 谁最需要它?
- ✅ 大数据专业学生:应付课程作业、实验报告,节省时间备考
- ✅ 课程设计者:作为实验案例模板,减少备课工作量
- ✅ 求职新人:积累电商实时分析项目经验,丰富简历
💡 一句话总结
不用再查零散教程、不用调试报错到凌晨!这份报告技术栈新、场景全、可复现,30 分钟搞定别人 3 天的工作量,作业提交直接拿高分!