文档定位:专为高校学生、大数据实验党打造的 Ubuntu 18.04 环境单节点 Hadoop 伪分布式集群 部署指南,精准匹配课程实验要求,覆盖 “环境搭建 – 配置 – 启动 – 任务测试” 全流程,搭配 20 + 张高清实操截图,零基础也能快速完成作业,轻松拿下实验满分!
一、文档核心价值(学生党刚需解决)
| 价值维度 | 具体说明 |
|---|---|
| 作业 / 实验 1:1 匹配 | 基于 Ubuntu 18.04 系统,步骤对应 “伪分布式集群搭建”“WordCount 任务提交” 等核心要求,按文档操作即可完成实验 |
| 零门槛避坑 | 涵盖 “Ubuntu 虚拟机创建报错”“SSH 免密登录失败”“Hadoop 进程缺失” 等学生常见问题,操作即跳过试错环节 |
| 实验报告素材包 | 截图、配置代码、Web 界面成果可直接嵌入报告,节省 90% 整理时间,不用熬夜补素材 |
二、集群环境与实验要求一致(抄作业级配置)
| 配置项 | 实验标准配置 |
|---|---|
| 操作系统 | Ubuntu 18.04 LTS(高校实验环境标配,避免版本兼容问题) |
| IP 地址 | 静态 IP:192.168.184.135(附配置步骤,可按需调整) |
| 软件版本 | JDK 1.8(OpenJDK)+ Hadoop 3.3.6(稳定版,课程教学常用) |
| 集群模式 | 伪分布式集群(单节点模拟分布式环境,无需多台机器) |
三、文档内容架构(实验步骤清晰指引,含高清截图)
| 阶段 | 实验核心目标 | 关键操作(只说 “做什么”,清晰无冗余) |
|---|---|---|
| 1. 环境初始化 | 搭建 Ubuntu 18.04 基础环境,确保可远程操作 | ① 下载 Ubuntu 18.04 镜像,用 VMware 创建虚拟机 ② 配置静态 IP 与主机名,修改 /etc/hosts映射③ 用 Xshell 远程连接虚拟机 |
| 2. 依赖部署 | 安装 Hadoop 必需的 Java 与 Hadoop | ① 安装 OpenJDK 1.8,配置环境变量并验证 ② 下载 Hadoop 3.3.6,解压至指定目录并配置权限 |
| 3. 核心配置 | 完成伪分布式集群关键配置 | ① 编辑 3 个核心配置文件: – core-site.xml(指定主点) – mapred-site.xml(配置 YARN) – hdfs-site.xml(设置副本数)② 配置 SSH 免密登录(伪分布式必做) |
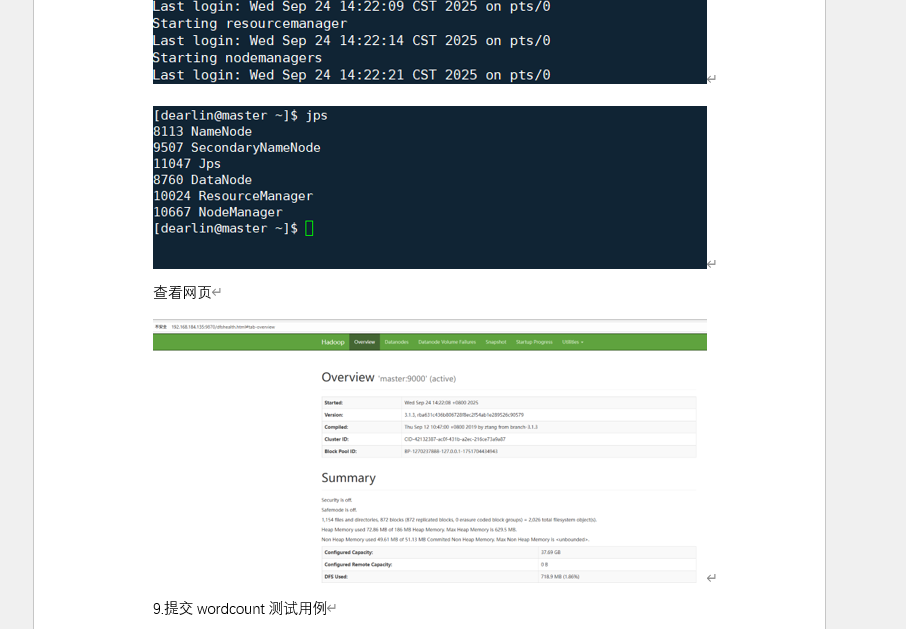
| 4. 启动与验证 | 启动集群 + 完成实验任务 | ① 格式化 HDFS 文件系统(初始化环境) ② 执行 start-all.sh启动集群,用jps验证进程③ 访问 Web 界面(9870 端口 HDFS、8088 端口 YARN) ④ 提交 WordCount 任务,查看执行结果 |
四、文档截图展示(付费可见・实验报告直接用)
以下为截图分类说明,完整截图 = 实验报告素材库,付费后直接插入报告!
| 截图分类 | 实验报告可用素材示例 |
|---|---|
| 环境配置类 | Ubuntu 18.04 镜像下载界面、VMware 虚拟机创建步骤、Xshell 远程连接成功界面 |
| 依赖安装类 | java -version验证截图、Hadoop 解压目录结构、环境变量配置界面 |
| 配置文件类 | 3 个核心配置文件完整编辑界面(带可复制代码)、SSH 免密登录成功提示 |
| 集群操作类 | HDFS 格式化日志、jps进程结果、WordCount 任务成功日志(map 100% reduce 100%) |
| Web 界面类 | HDFS 监控界面(集群容量)、YARN 任务界面(任务 “FINISHED” 状态)、结果 Web 查看界面 |
五、适合人群(学生党专属定位)
- 大数据 / 计算机专业学生:完成 “单节点 Hadoop 伪分布式集群搭建”“MapReduce 编程” 等课程实验,轻松拿满分
- 作业赶工党:应付 “大数据技术基础”“分布式系统” 等课程作业,避免因 “系统不兼容” 熬夜卡壳
- 毕设 / 课程设计党:快速搭建 Ubuntu 18.04 伪分布式环境,作为毕设 “大数据模块” 基础,节省部署时间
六、付费可见内容(实验高分必备)
- 20 + 张 Ubuntu 18.04 专属高清截图(含虚拟机创建、配置编辑、Web 界面,直接插入报告)
- 3 个核心配置文件 完整可复制代码(不用手动敲写,避免语法错误)
- 实验 关键步骤验证指南(如 “jps 进程不全排查”“WordCount 报错解决”)
- Web 界面 访问教程(含 IP + 端口说明、界面信息解读,报告截图更专业)



付费后可获取完整文档(截图 + 代码 + 指南),支持本地保存为 PDF,实验时边看边做,别人还在纠结 Ubuntu 配置,你已经提交完作业躺平了!