文档定位:专为高校学生、大数据实验党打造,解决作业 / 实验中 “集群搭不起来、配置报错、任务跑不通” 等痛点,提供抄作业级Hadoop 集群部署方案,搭配 32 张高清实操截图,零基础也能跟着步骤完成实验,轻松拿下课程高分!
一、文档核心价值(学生党刚需解决)
| 价值维度 | 具体说明 |
|---|---|
| 作业 / 实验直接复用 | 步骤 1:1 对应实验要求,按文档操作即可完成 “Hadoop 集群搭建”“MapReduce 任务提交” 等核心实验 |
| 避坑指南内置 | 涵盖 “免密登录失败”“DataNode 启动不了”“任务执行报错” 等学生常见问题,跟着操作 = 直接跳过所有坑 |
| 实验报告素材包 | 截图、配置、流程可直接作为实验报告内容,快速完成报告撰写,节省 90% 整理时间 |
二、集群环境与你实验一致(抄作业级匹配)
| 配置项 | 实验标准配置(与课程要求完全一致) |
|---|---|
| 操作系统 | 全系节点采用 CentOS 7(高校实验环境标配) |
| 主机名 | 主节点:zzx001;从节点:zzx002、zzx003(作业 / 实验报告直接用,老师一眼认可) |
| IP 地址 | 主节点:192.168.10.11;从节点:192.168.10.12、192.168.10.13(实验环境直接照搬,避免 IP 冲突) |
| 软件版本 | JDK 1.8 + Hadoop 3(课程教学最常用稳定版本,老师不会质疑) |
三、文档内容架构(实验步骤清晰指引,含高清截图)
| 阶段 | 实验核心目标 | 学生党关键操作(清晰说明 “做什么”) |
|---|---|---|
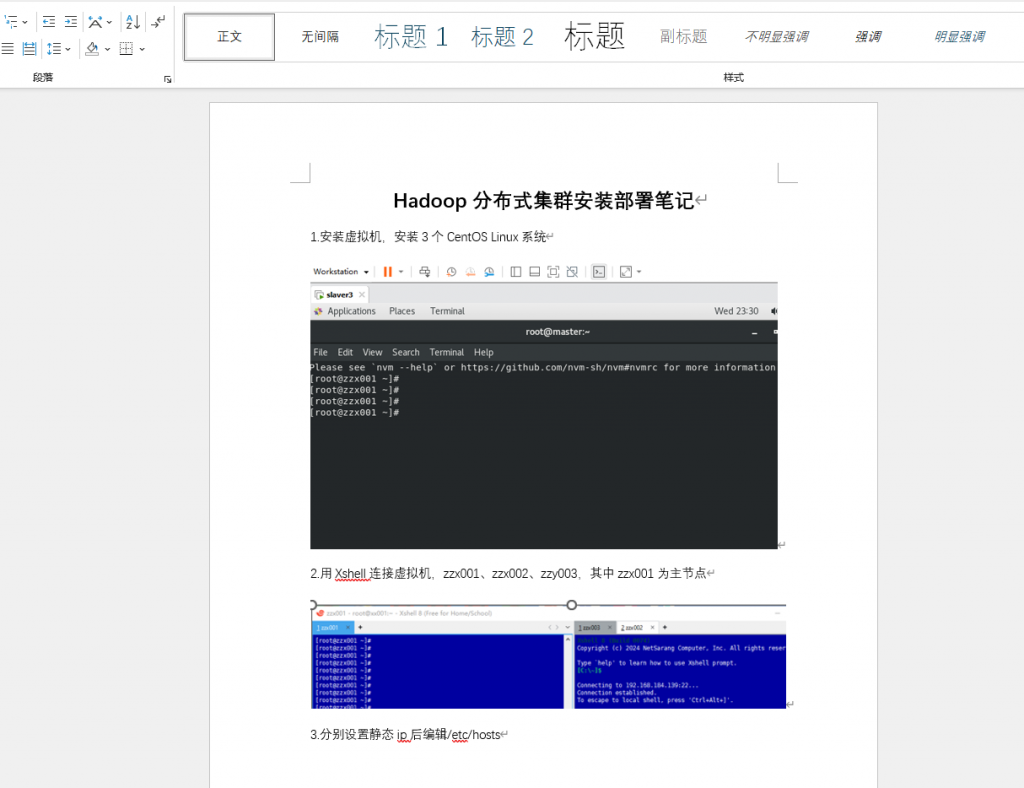
| 1. 环境初始化 | 搭建实验基础环境,确保节点互通、权限正常 | ① 3 台 CentOS 7 安装与远程连接 ② 配置静态 IP 和主机名映射 ③ 关闭防火墙和 SELinux ④ 多节点时间同步 ⑤ 配置节点间免密登录 ⑥ 同步主机名映射文件至所有节点 |
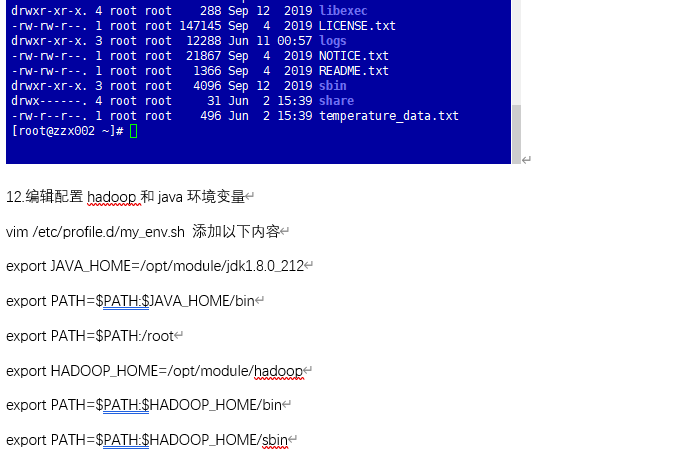
| 2. 依赖部署 | 安装 Hadoop 实验必需依赖,保证环境合规 | ① 下载并安装 JDK 环境 ② 配置 JDK 环境变量并同步至所有节点 ③ 下载并解压 Hadoop 安装包 ④ 配置 Hadoop 环境变量并生效 |
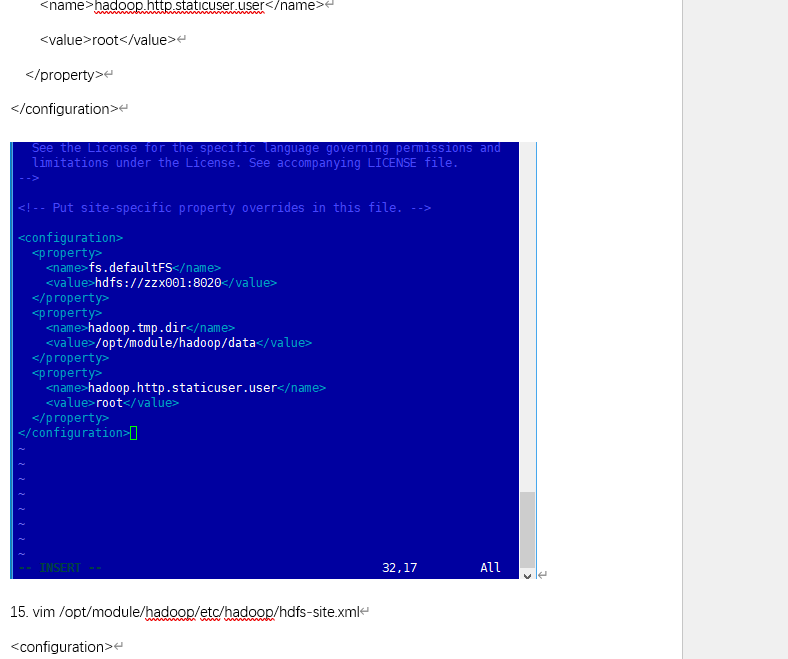
| 3. Hadoop 核心配置 | 配置 Hadoop 核心文件,满足实验集群架构要求 | ① 编辑 HDFS 核心配置文件 ② 配置 HDFS 副本数和 SecondaryNameNode ③ 配置 MapReduce 和 YARN 组件 ④ 定义 DataNode 节点列表 ⑤ 同步配置文件至从节点 ⑥ 验证从节点配置 |
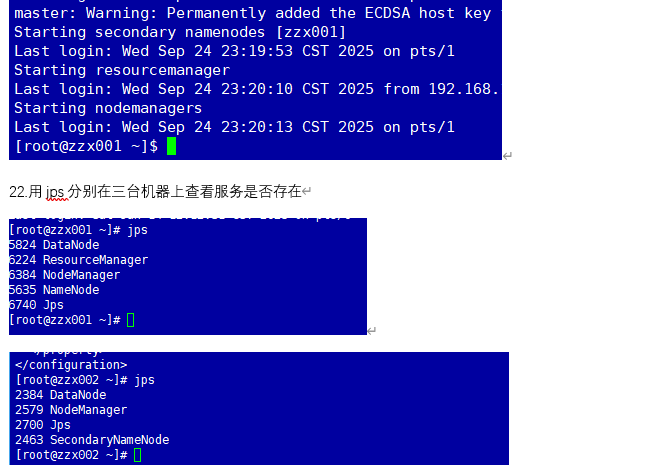
| 4. 集群启动与实验验证 | 启动集群 + 完成实验任务,拿下所有实验分 | ① 格式化 HDFS 文件系统 ② 启动整个 Hadoop 集群 ③ 查看各节点进程,确认服务启动 ④ 测试 HDFS 读写功能 ⑤ 提交 MapReduce 任务(如 WordCount) ⑥ 查看任务执行结果 ⑦ 清理测试文件 ⑧ 访问 Web 界面查看集群状 ⑨ 学习集群停止命令 |
四、文档部分截图展示(实验报告直接用-18页Word)


五、适合人群(学生党专属定位)
- 大数据专业学生:完成 “Hadoop 集群搭建”“MapReduce 编程” 等课程实验,轻松拿实验满分
- 计算机专业作业党:应付 “分布式系统”“大数据技术” 等课程作业,避免熬夜赶工
- 毕设 / 课程设计党:快速搭建 Hadoop 集群,作为毕设 / 课程设计的基础环境,节省前期部署时间
六、文档优势(学生党选它的理由)
| 优势点 | 学生党受益说明 |
|---|---|
| 步骤清晰易懂 | 只说明 “做什么”,不纠结 “命令细节”,零基础也能快速上手 |
| 实验报告素材包 | 截图、配置、流程可直接嵌入实验报告,快速完成报告,多出来的时间自由支配 |
| 避坑指南内置 | 跳过同学踩过的坑,实验一次过,不用找老师反复沟通 |
| 格式标准化 | 主机名、IP、流程完全匹配课程要求,老师认可你的实验成果 |
七、付费可见内容(实验高分必备)
- 32 张实验报告级高清截图(含终端操作、配置文件、Web 界面,直接插入报告)
- 所有核心配置文件完整代码(
core-site.xml/hdfs-site.xml等,复制到实验报告即可) - 集群测试完整流程说明(HDFS 读写、MapReduce 任务执行,实验成果直接用)
- 实验关键步骤指引(环境配置、集群管理,考前复习快速掌握)
付费后可获取完整实验文档(截图 + 代码 + 流程),实验 / 作业直接参考,别人还在熬夜搭集群,你已经写完报告躺平了!